Most people think interoperability means systems can connect. APIs talk, databases link, pipelines run—and on paper, everything “works.” But connection isn’t the same as interoperability.
True interoperability shows up at the output. It’s not about whether data can be brought together—it’s about whether it can be used together immediately, without transformation, interpretation, or risk.
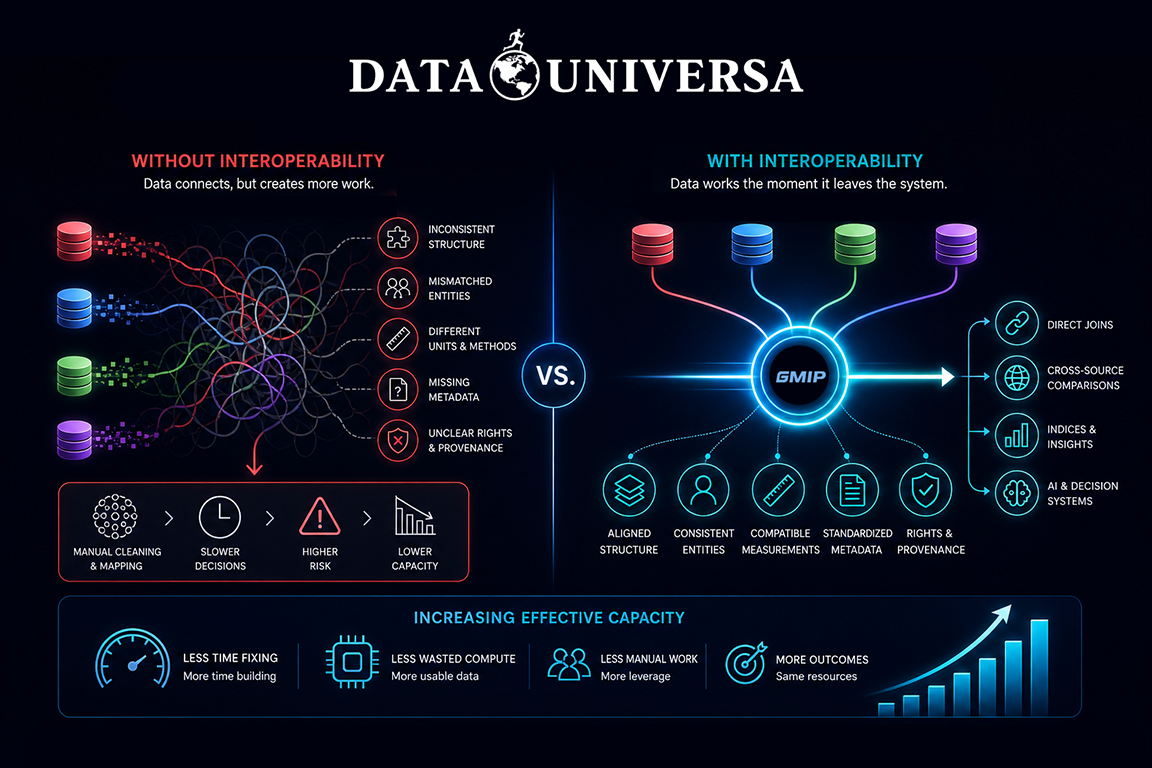
In most environments, combining datasets introduces friction instead of removing it. Structure doesn’t align, definitions drift, units vary, and context is incomplete. Even when data technically connects, teams still have to step in—cleaning, mapping, and reconciling before anything becomes usable. That extra layer is so common it’s often treated as normal. It shouldn’t be.
Interoperability, properly defined, exists only when that layer disappears—when datasets can be directly combined, compared, and reused across systems without additional handling. The output works on the first pass. This distinction has a broader impact than it might seem.
When interoperability is missing, systems consume capacity just to maintain themselves. Engineering time goes into fixing inconsistencies instead of building new capabilities. Compute is spent reprocessing and validating data that should have already been usable. Decisions are delayed because outputs can’t be trusted without further work.
When interoperability is present, that waste is removed. Processes that used to require multiple steps collapse into one. Data moves directly into analysis, AI models, or decision systems without needing translation layers. The same infrastructure and teams can produce more outcomes, not because they’ve expanded, but because less effort is lost.
This is what increasing effective capacity actually looks like. Not scaling resources, but reducing friction.