Most companies think about capacity in the wrong units. They measure it in infrastructure, headcount, and compute. More servers, more engineers, more pipelines. On paper, capacity increases every year. In practice, very little of it translates into usable output.
This is the gap between installed capacity and effective capacity.
Effective capacity is not what a system can do—it is what it can reliably produce without friction. It is the percentage of your total data and compute stack that actually results in usable, trusted outputs. In most organizations, that percentage is far lower than anyone expects.
How Companies Try to Increase Effective Capacity Today
There are a few common approaches companies take when they realize their systems are underperforming.
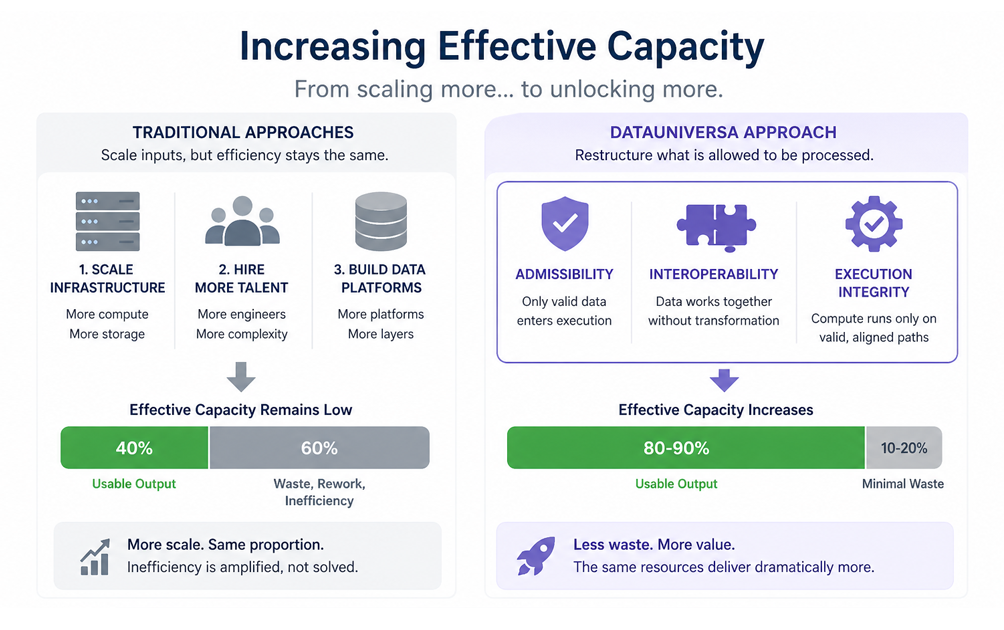
1. Scaling Infrastructure
The most straightforward response is to add more compute resources; Cloud expansion, GPU clusters, distributed processing frameworks.
This works, but only at the surface level.
If underlying data is inconsistent, poorly structured, or non-interoperable, additional compute simply processes inefficiency faster. The system grows, but the proportion of usable output often remains unchanged.
2. Hiring More Engineering Talent
Organizations also attempt to solve the problem with people. Data engineers, ML engineers, platform architects.
These teams spend significant time on:
- reconciling mismatched schemas
- debugging joins across fragmented datasets
- rebuilding pipelines for slightly different data variations
The result is incremental improvement, but at a high cost. Human capital is applied to maintain system stability rather than expand capability.
3. Building Internal Data Platforms
Many companies invest heavily in centralized data platforms, data lakes, warehouses, and governance layers. These systems improve access and visibility, but they rarely solve the core issue: data that looks unified is not necessarily functionally interoperable.
Without strict standards for structure, admissibility, and execution, these platforms still rely on continuous transformation and manual alignment.
The Limitation of These Approaches
All three strategies share a common assumption: That effective capacity is a function of scale.
Scale does not eliminate inefficiency, it often amplifies it. If 40% of your system produces usable output, doubling infrastructure does not change that ratio. It simply doubles both the productive and unproductive portions.
Effective capacity remains constrained.
DataUniversa: A Different Approach
DataUniversa introduces a fundamentally different way to increase effective capacity, not by scaling inputs, but by restructuring how data is allowed to exist and interact.
At its core, DataUniversa enforces:
- Admissibility — Data must meet defined criteria before entering execution
- Interoperability — Data is structured so it can be combined without transformation
- Execution Integrity — Compute is only allowed on valid, aligned data paths
How Effective Capacity Increases
When these constraints are applied, several things happen simultaneously.
Invalid work is eliminated
Compute is no longer wasted on data that cannot produce reliable outputs. Entire classes of processing, debugging, reconciliation, failed joins, are removed before they begin.
Transformation overhead collapses
Because data is structured to be interoperable from the outset, repeated transformations disappear. Pipelines become shorter, simpler, and more reusable.
Output reliability increases
When only admissible data is used, outputs become consistent and repeatable. This reduces downstream validation effort and increases trust in results.
Engineering effort shifts
Engineers move away from maintenance and toward creation. Instead of fixing pipelines, they build new capabilities on top of a stable foundation.
>>The Result<<
Effective capacity does not increase incrementally, it expands structurally.
The same infrastructure produces more usable output.
The same teams deliver more meaningful work.
The same datasets generate more value.
Not because more resources were added, but because less was wasted.
A New Framing
For years, companies have treated capacity as something to accumulate. DataUniversa reframes it as something to unlock.
The constraint is not how much compute you have. It is how much of that compute is operating on data that can actually produce value. Increase that proportion, and capacity follows.
For the first time, effective capacity becomes a controllable variable, not an emergent limitation.